

ABOUT US
The Visual and Multimodal Applied Learning Lab (VANDAL) focuses on developing innovative, robust, and efficient machine learning models that process and integrate visual and multi-modal signals. By harnessing perceptual intelligence and formalizing it into advanced algorithms and frameworks, we aim to empower artificial agents with the ability to understand and interpret the world around them, facilitating natural interactions with the environment. Our ultimate goal is to enable these agents to perform complex real-world tasks autonomously while learning in an open-ended manner, fostering adaptability and reliability.
VANDAL research encompasses a broad spectrum of applications in computer vision and robotics, spanning spatial localization, ego and exo-centric video analysis, comprehensive 2D/3D scene understanding, distributed learning with privacy-preserving constraints, as well as robotic grasping, manipulation, and navigation.
OUR MAIN AREAS OF RESEARCH
3D Learning

The goal of 3D deep learning is to adapt current computer vision technologies to work with 3D data, tackling challenges such as data sparsity and density variation, non-Euclidean geometry, and high dimensionality. Unlike 2D approaches, which overlook real-world complexities, 3D deep learning leverages point clouds and depth images to capture rich spatial information unavailable in classic RGB images. This enables spatial reasoning and fine-grained interactions crucial for robotic tasks such as grasping and object manipulation. In autonomous driving, 3D deep learning is particularly valuable, processing LiDAR data to capture precise spatial information about the environment. Our goal is to design smart models to face tasks such as 3D object recognition, segmentation, generation, and completion as well as pose estimation, registration, and alignment.
Scene Understanding

Scene understanding is the key to unlocking the potential of intelligent systems, enabling machines to interpret and interact with their surroundings. This involves various subtasks such as image segmentation (classifying pixels into categories), anomaly segmentation (detecting the unexpected), and referring segmentation (finding objects based on textual descriptions), each contributing to a comprehensive understanding of the scene. Applications of scene understanding span numerous fields, including autonomous driving, where vehicles need to accurately identify and respond to objects and obstacles. However, achieving effective scene understanding presents several challenges, such as dealing with diverse and complex environments, ensuring real-time processing capabilities, and maintaining high accuracy in diverse conditions. Addressing these challenges requires advanced algorithms and robust models capable of handling the variability and intricacies of real-world scenes with particular attention to designing innovative efficient solutions.
Robot Learning

Despite recent breakthroughs in AI, we have yet to come across applications of Machine Learning that bring fully autonomous robots into our everyday lives. Our research on Robot Learning aims to develop the next generation of data-driven algorithms for embodied systems — such as robotic arms — to effectively scale the complexity of tasks to, and beyond, human capabilities. This objective includes allowing robots to reason like humans in terms of task planning, encouraging human-like behavior when solving a task for better cooperation, and being able to generalize and adapt to different tasks, environments, and dynamics. To this end, we investigate novel ways to solve robotic manipulation tasks by leveraging simulated environments and Reinforcement Learning, as well as designing state-of-the-art algorithms for autonomous robotic grasping and spray painting in complex real-world scenarios.
Video Understanding

Starting from a video, recognizing actions, understanding human-object interactions, and predicting what will happen next require spatial and temporal reasoning about the available multi-modal content, as well as structured reasoning about the high-level patterns behind human activities. In particular, egocentric videos offer a privileged first-person point of view to understand how biological agents act, which is then essential to transfer knowledge to robots. At the same time, egocentric videos come with several key challenges as head motion, occlusions, and data scarcity which make it a very challenging setting. Our work in this area aims at pushing research boundaries toward models able to manage such complex scenarios and lay the foundations for life-long-learning artificial agents.
Visual place recognition

Mapping images to places is a key problem that underpins several applications, ranging from robotics to augmented reality for assistive devices. A place can be defined in different ways. For instance, Landmark Retrieval aims to search for the most similar sample in a database of annotated landmark images. This enables recognizing the name of the testing landmark but its coordinates are usually not considered. In Visual Geolocalization instead, the goal is to estimate the coordinates (e.g., GPS or UTM) where a picture was taken, based solely on visual clues. In urban applications, the expected accuracy is in the range of meters (typically 25 meters). Even this task is usually cast as an Image Retrieval problem, where the query to be localized is compared to a database of geotagged images, exploiting a representation extracted with a neural network. We are interested in developing accurate and efficient models to manage visual place recognition and geolocalization at a large scale for real-world city-wide applications.
Distributed and Federated Learning
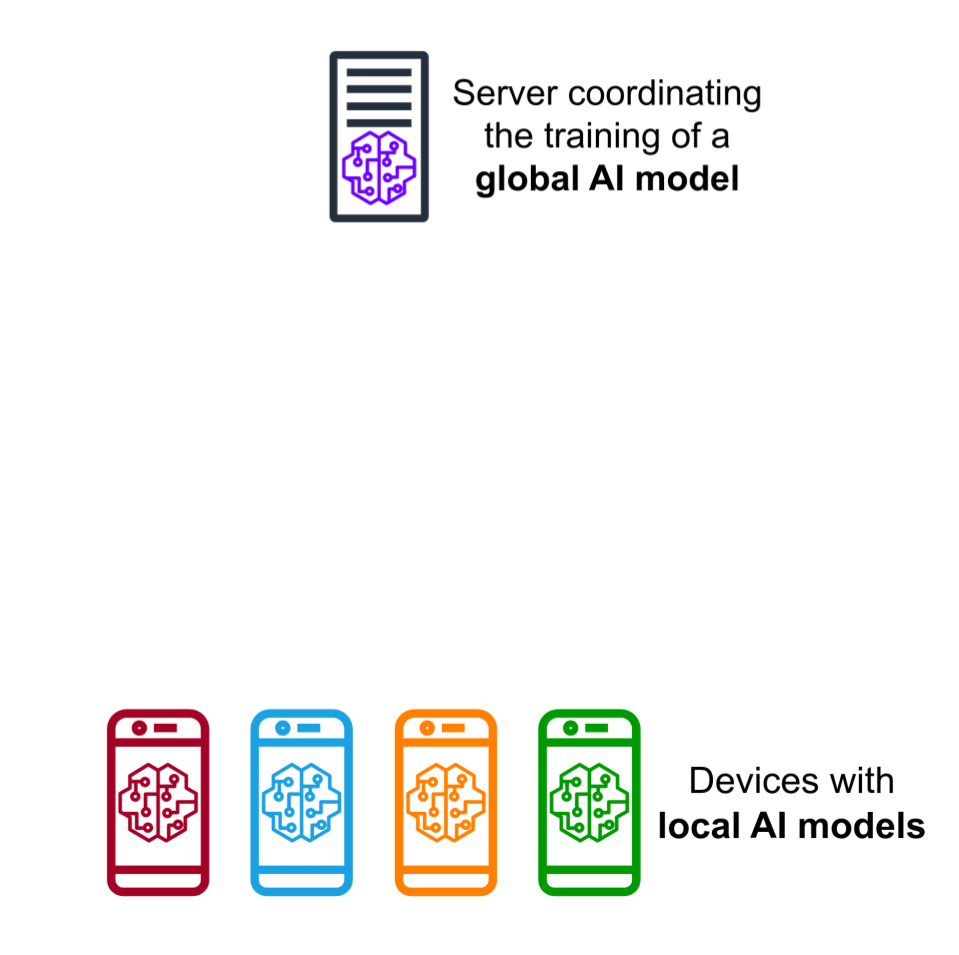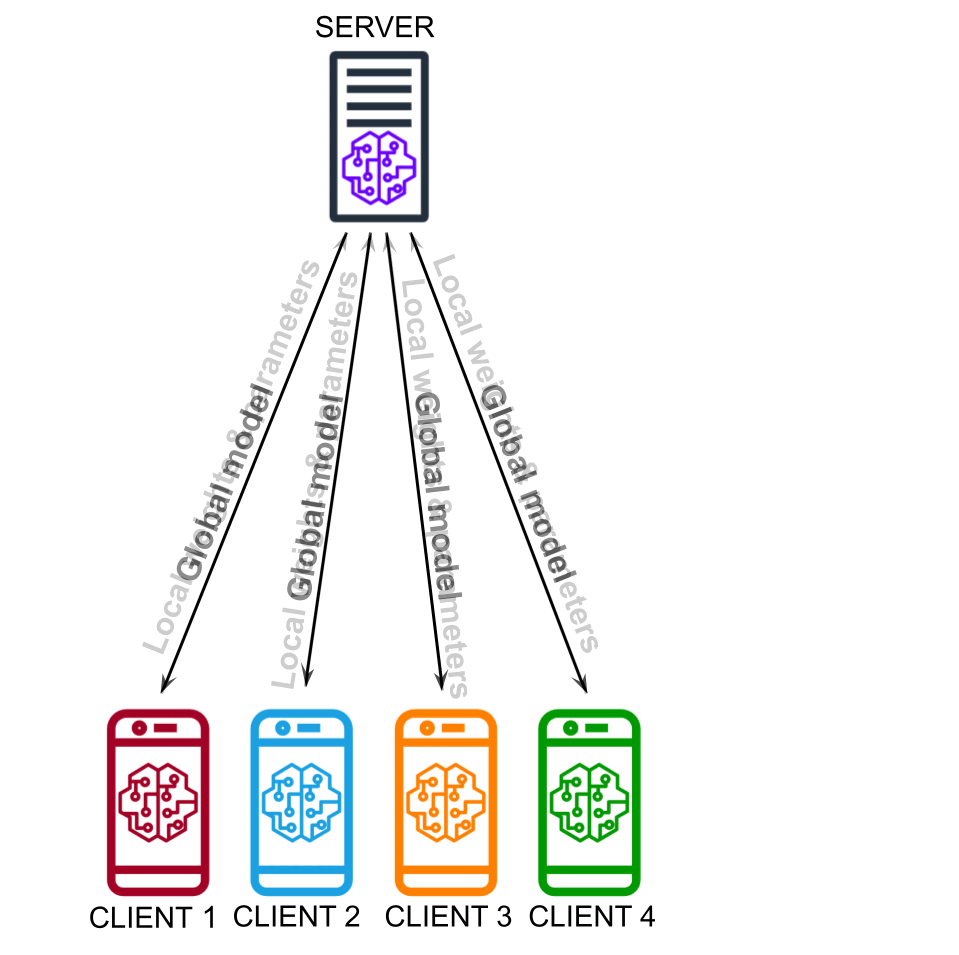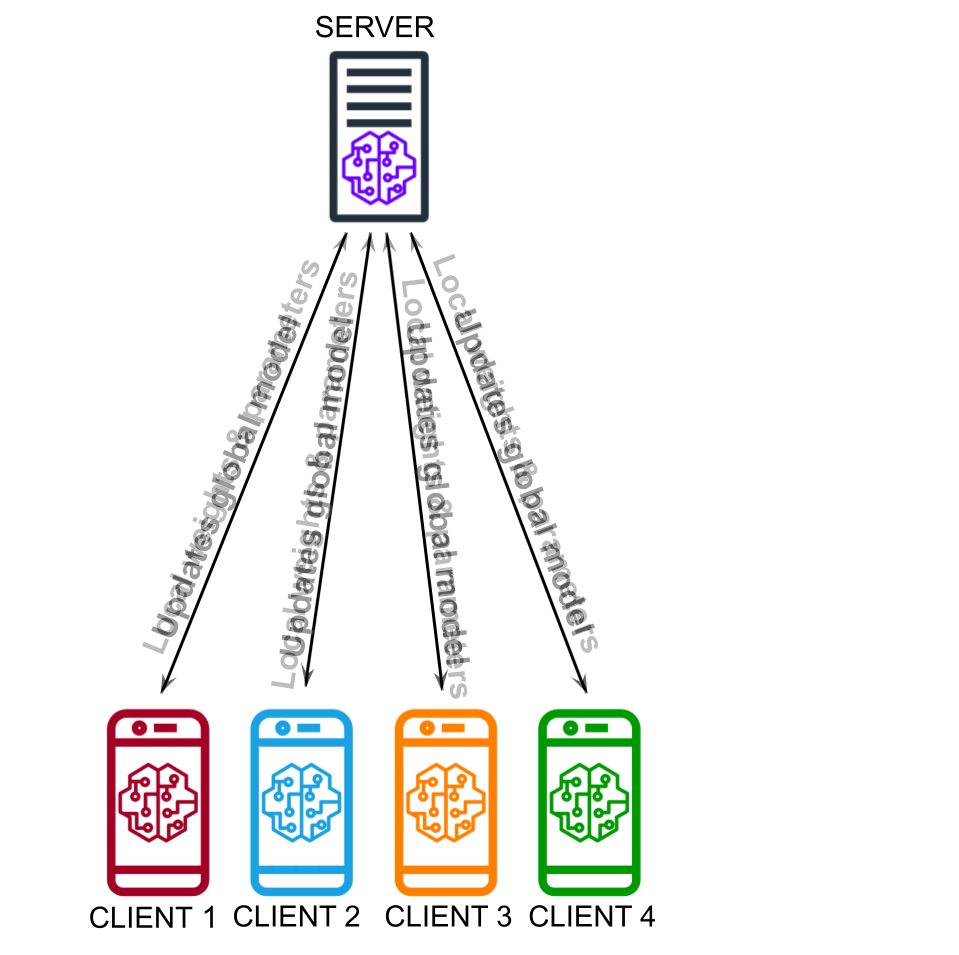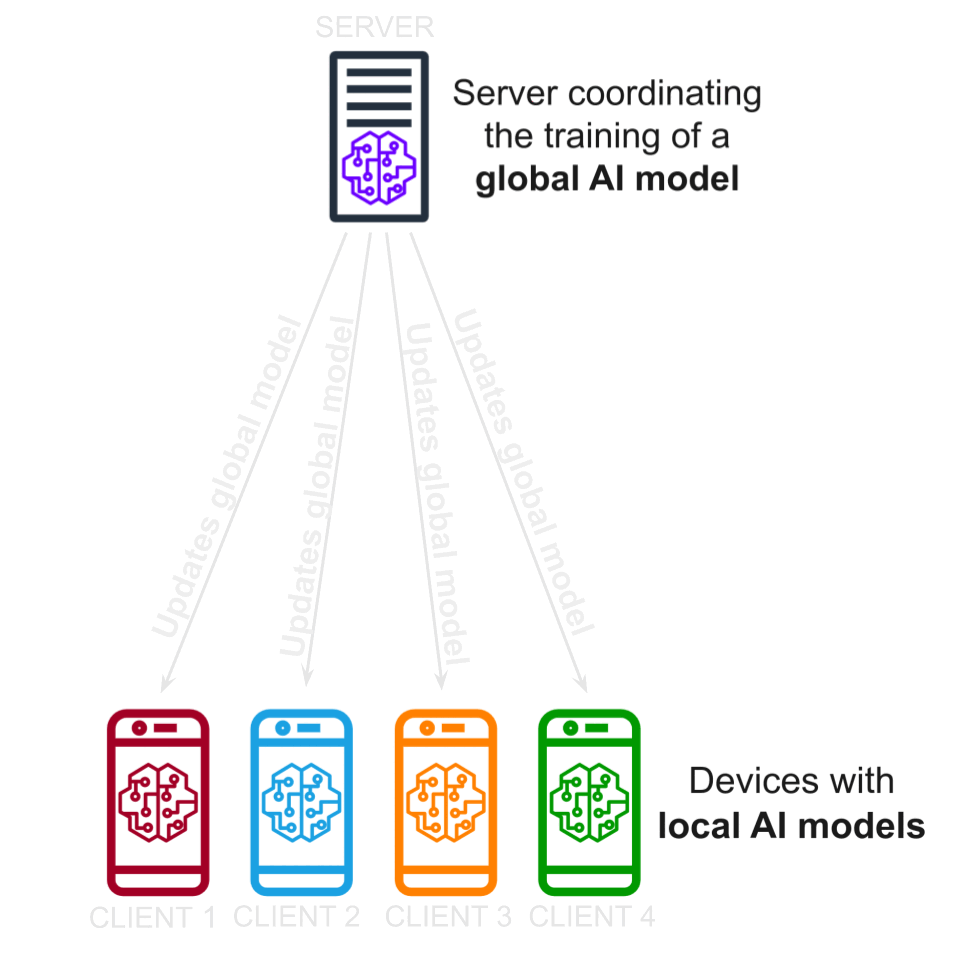
Recent breakthroughs enabled by deep learning rely on increasingly complex architectures: the advent of Large Language Models (LLMs) has marked a new chapter for conversational agents like ChatGPT, but also introduced real challenges in training and serving such solutions for real-world applications. Therefore, scaling data and computing power are crucial for successful training, but speed-up scaling laws are not going to cope forever with the limits of current algorithms and architectures. Moreover, the centralized training paradigm no longer matches the needs of modern applications, which elaborate on heterogeneous data often scattered across large networks. We investigate the problem of distributed and federated learning of deep neural networks, aiming to develop novel fully decentralized algorithms and model architectures that meet the demands of next-generation deep learning applications.
Trustworthy and Fair AI models

The widespread adoption of AI systems in decision-making processes has underscored the urgent need to ensure reliability and fairness. Studying model accuracy is not enough as the overall performance may hide the use of spurious correlations in the data which cause biased predictions with high-impact consequences on society. Moreover, to flawlessly move algorithms out of lab environments, we should make sure their performance remains consistent and dependable across diverse scenarios, even in the presence of novel conditions unpredictable at training time. These premises indicate a clear need for trustworthy models assessed under different metrics and possibly coming with confidence guarantees. Our work focuses on vision and multi-modal learning approaches that incorporate fairness-aware strategies, robust evaluation frameworks, and tailored techniques for adaptation, robustness, and transparency.